# A tibble: 103 x 8
id acceptyear age survived survtime prior transplant wait
<int> <int> <int> <fct> <int> <fct> <fct> <int>
1 15 68 53 dead 1 no control NA
2 43 70 43 dead 2 no control NA
3 61 71 52 dead 2 no control NA
4 75 72 52 dead 2 no control NA
5 6 68 54 dead 3 no control NA
6 42 70 36 dead 3 no control NA
7 54 71 47 dead 3 no control NA
8 38 70 41 dead 5 no treatment 5
9 85 73 47 dead 5 no control NA
10 2 68 51 dead 6 no control NA
# ... with 93 more rowsLogistic Regression
STA 101L - Summer I 2022
Example – Stanford University Heart Transplant Study
Goals: to determine whether an experimental heart transplant program increases lifespan
observations: patients
response: survival after 5 years (binary)
predictors: age, prior surgery, waiting time for transplant.
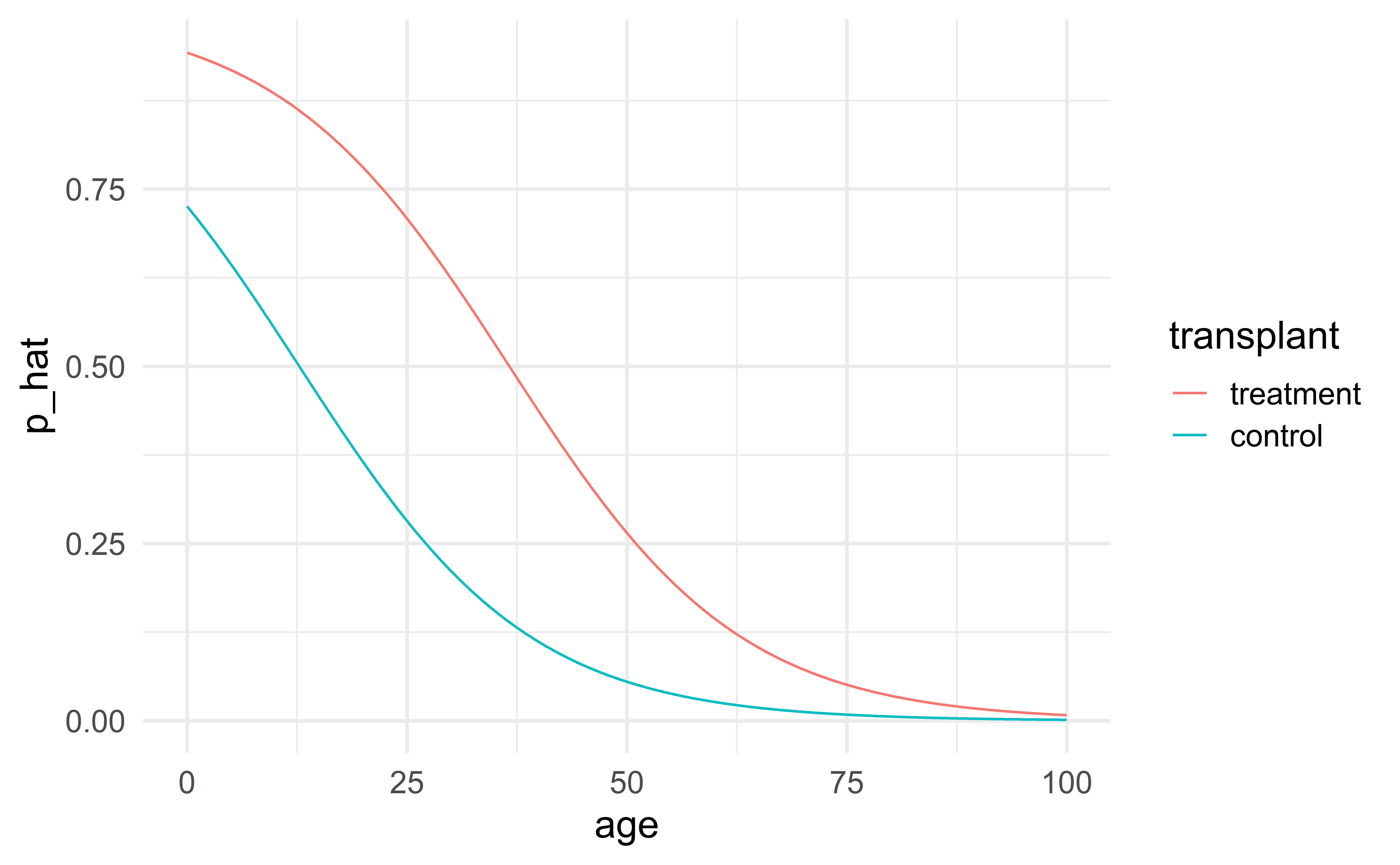
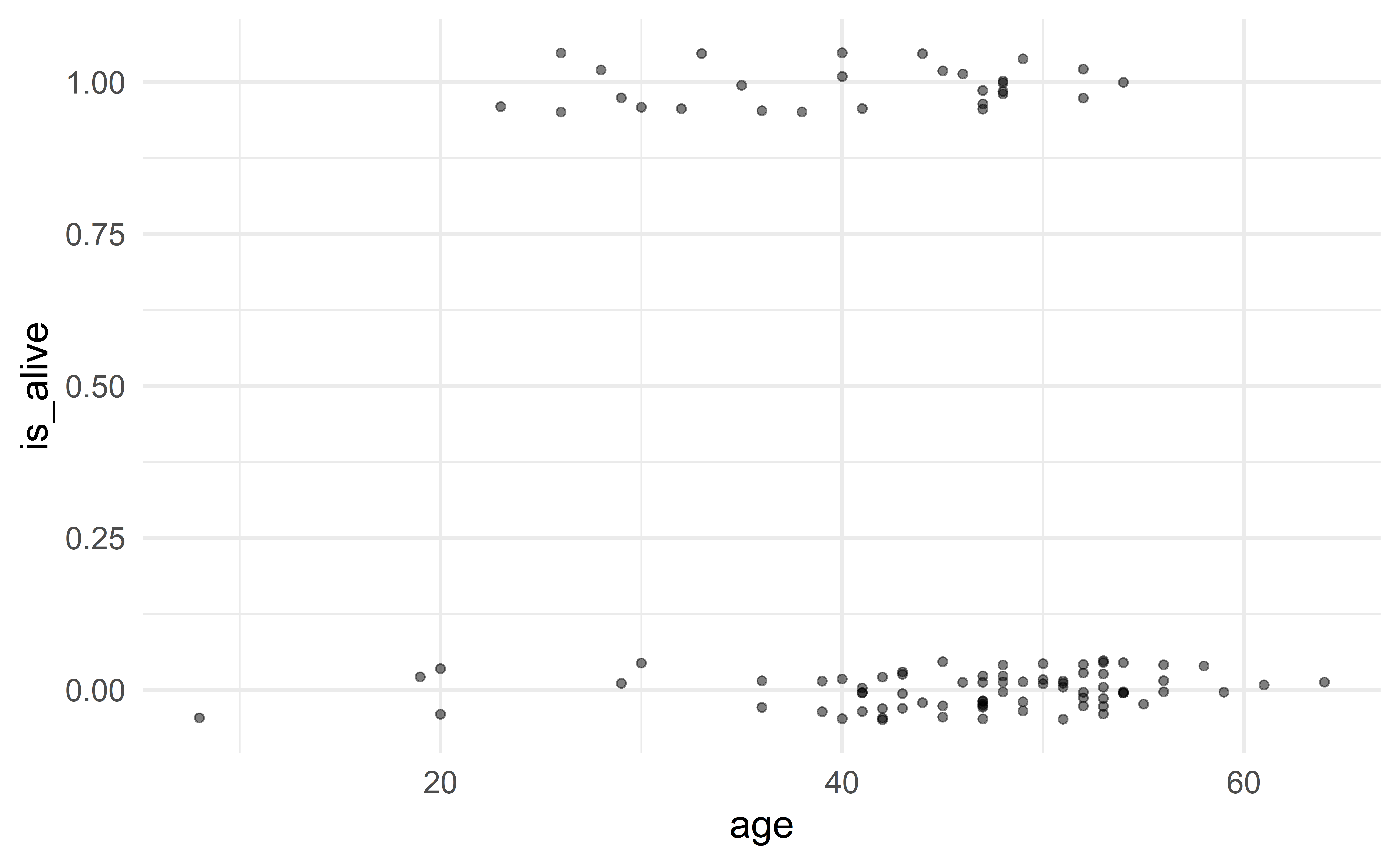
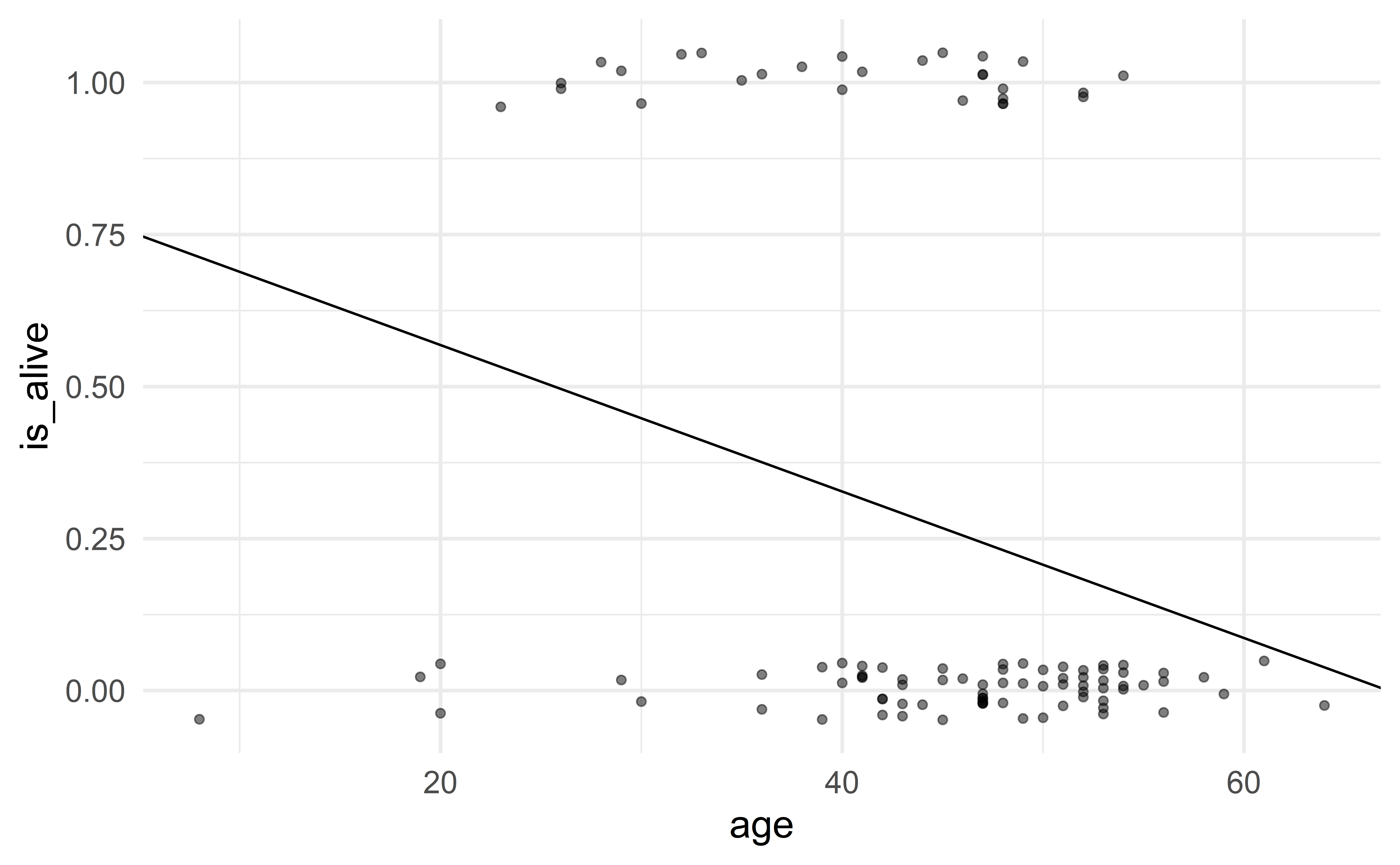
Effect of age on survival
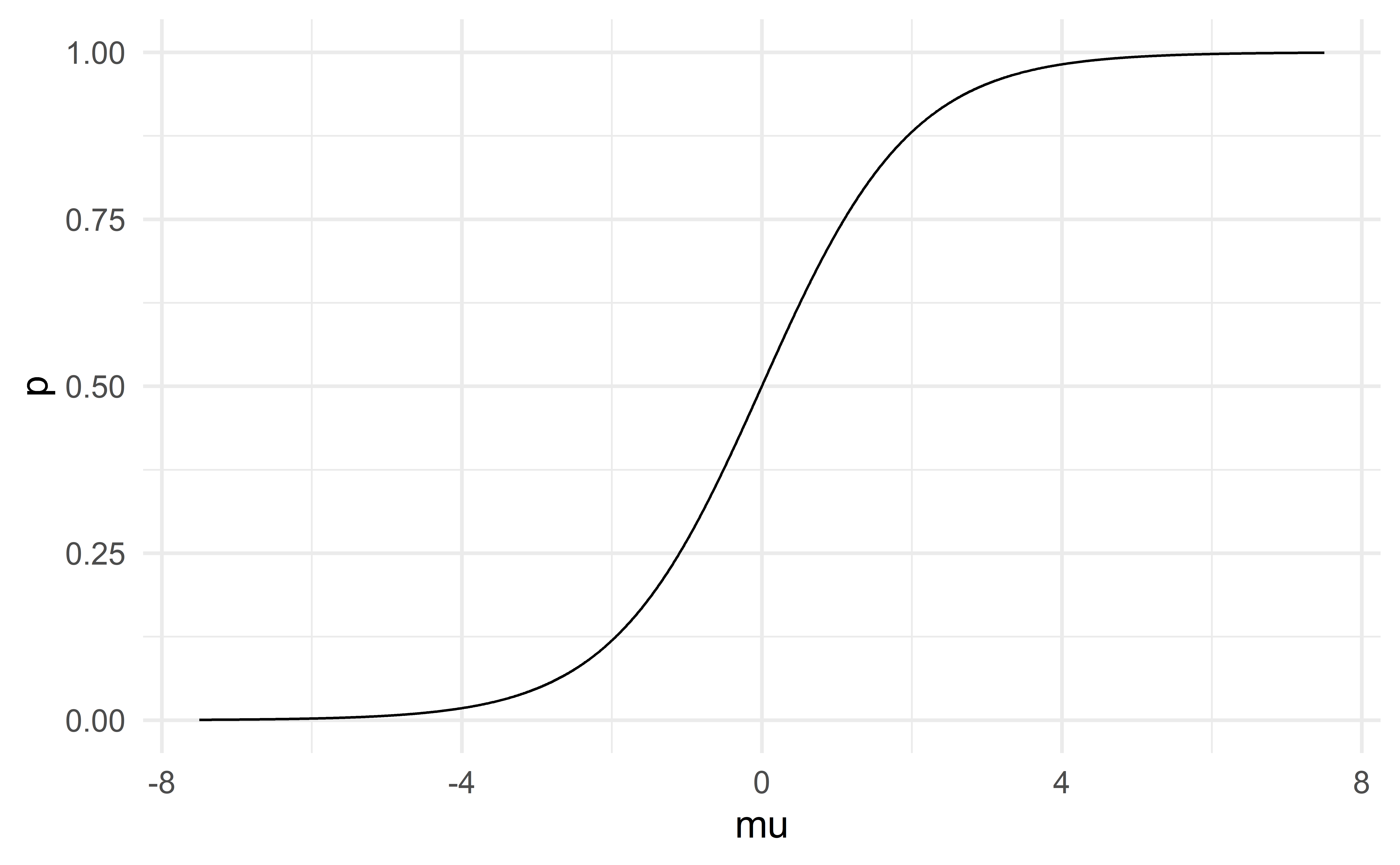
Note that \(\dfrac{e^{\mu}}{1+e^{\mu}}\) is bounded between 0 and 1.
Moreover, larger values of \(\mu\) will give larger \(p\), and smaller \(\mu\) will give smaller \(p\).
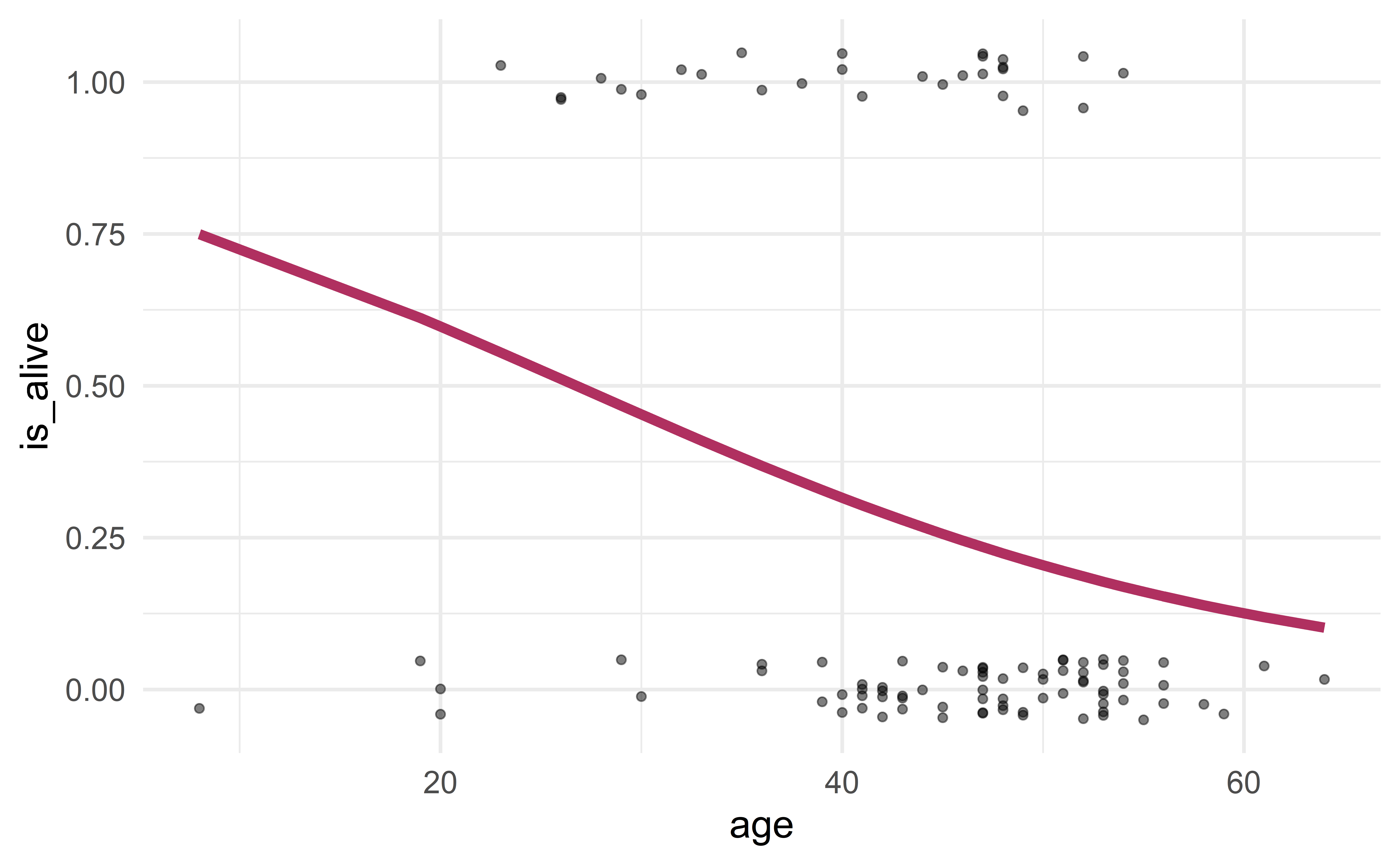
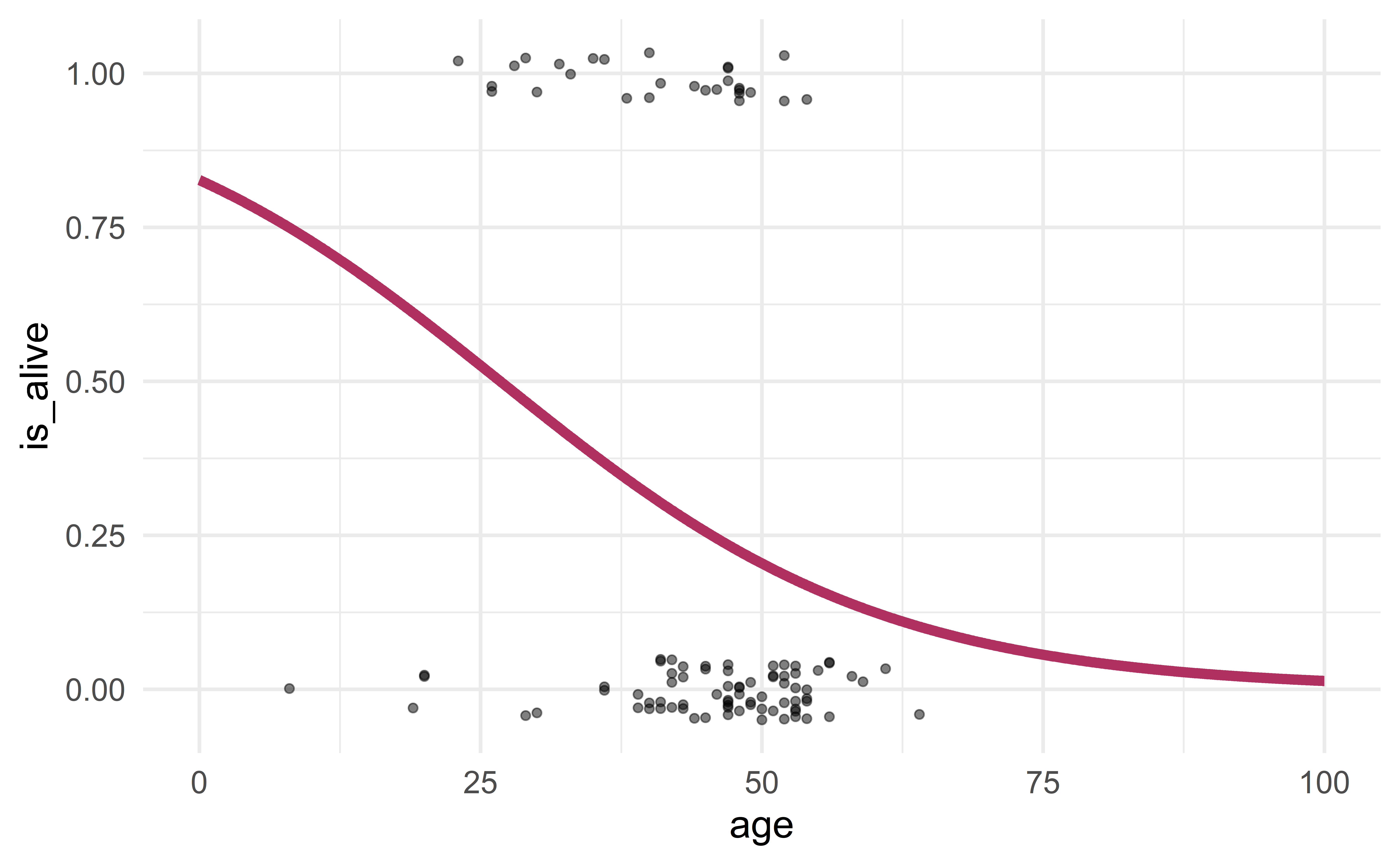
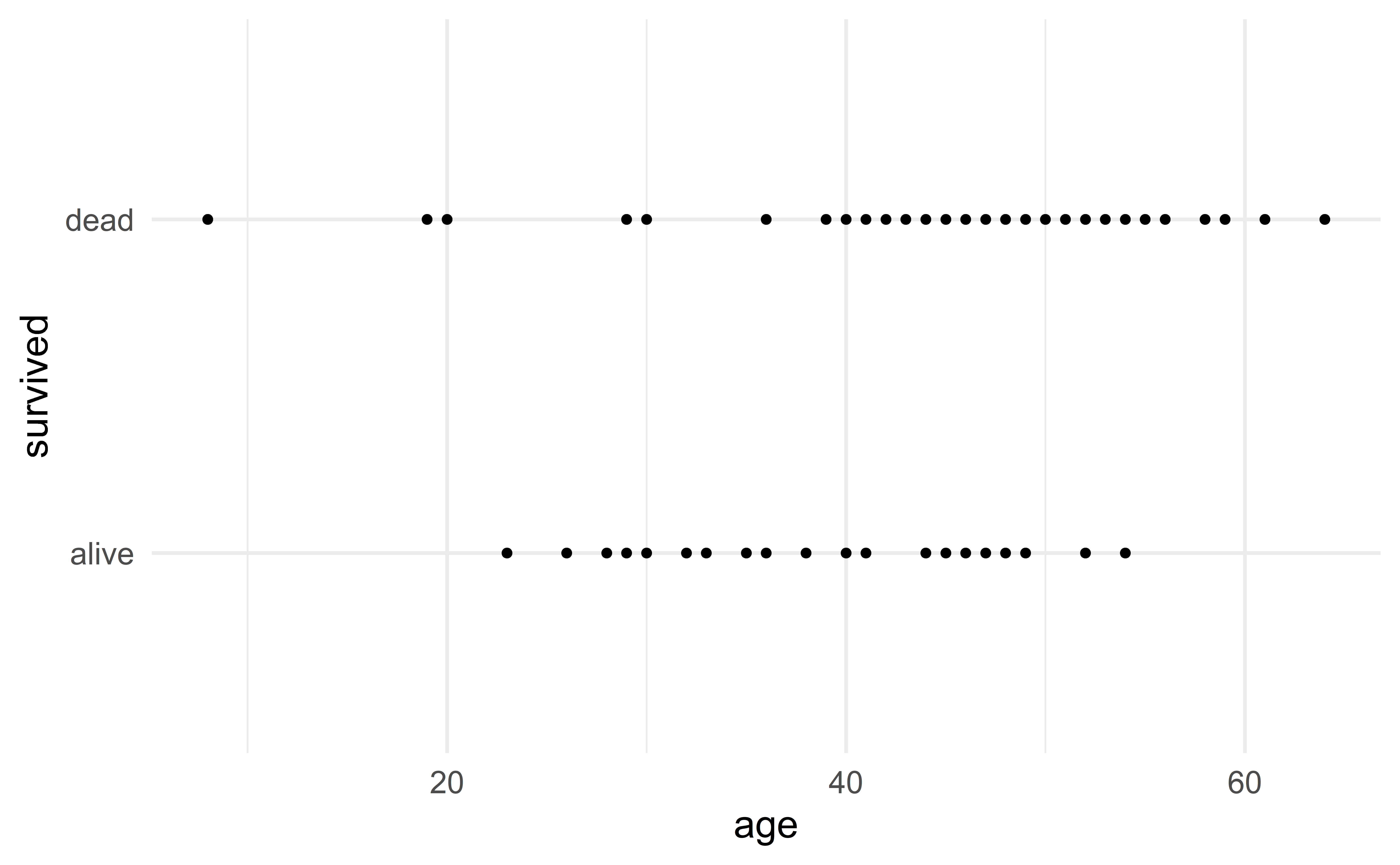
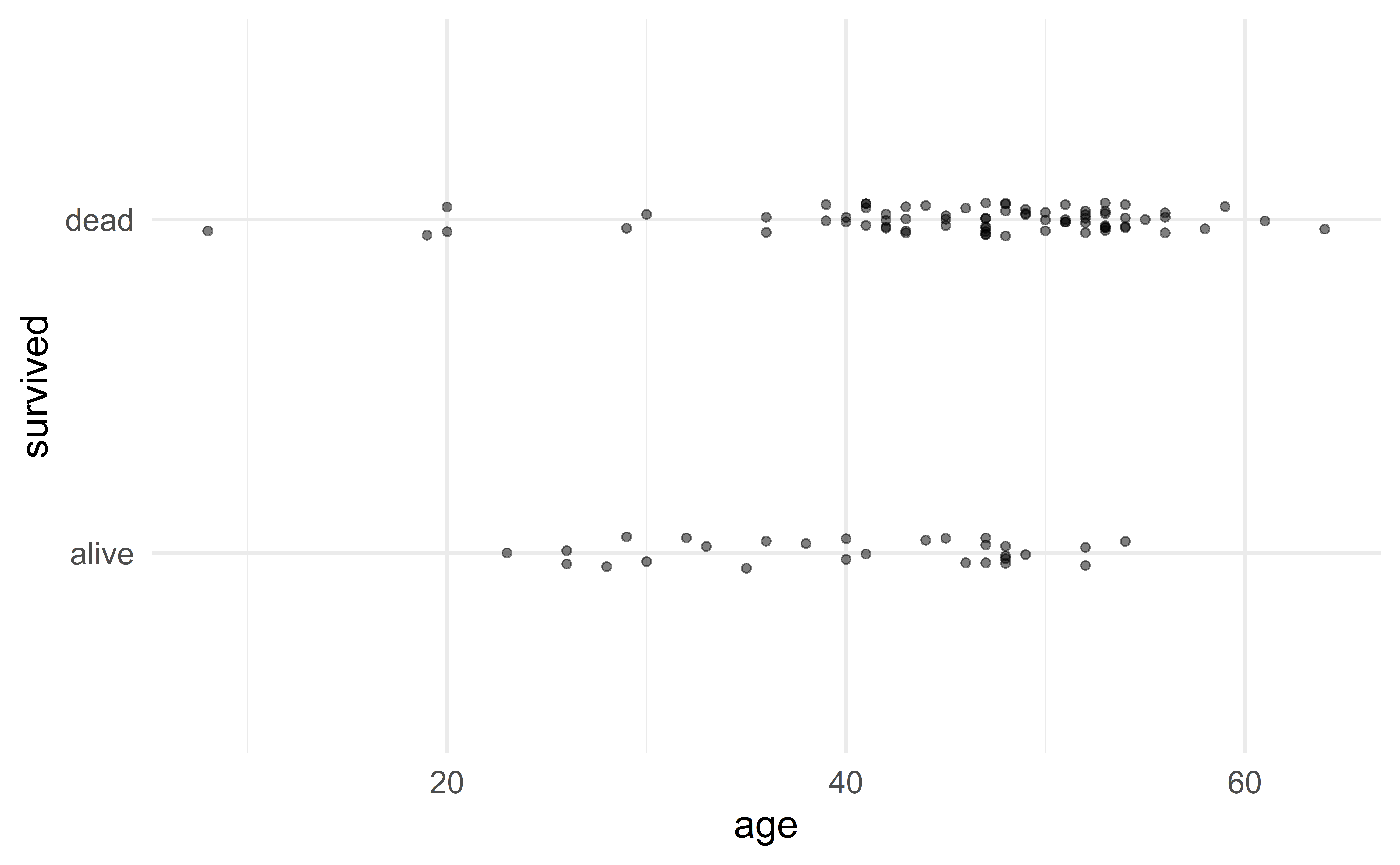
Visualization