# A tibble: 4 x 11
manufacturer model displ year cyl trans drv cty hwy fl class
<chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
1 audi a4 1.8 1999 4 auto(l5) f 18 29 p compa~
2 audi a4 1.8 1999 4 manual(m5) f 21 29 p compa~
3 audi a4 2 2008 4 manual(m6) f 20 31 p compa~
4 audi a4 2 2008 4 auto(av) f 21 30 p compa~Simple Linear Regression Models
STA 101L - Summer I 2022
Simple linear regression
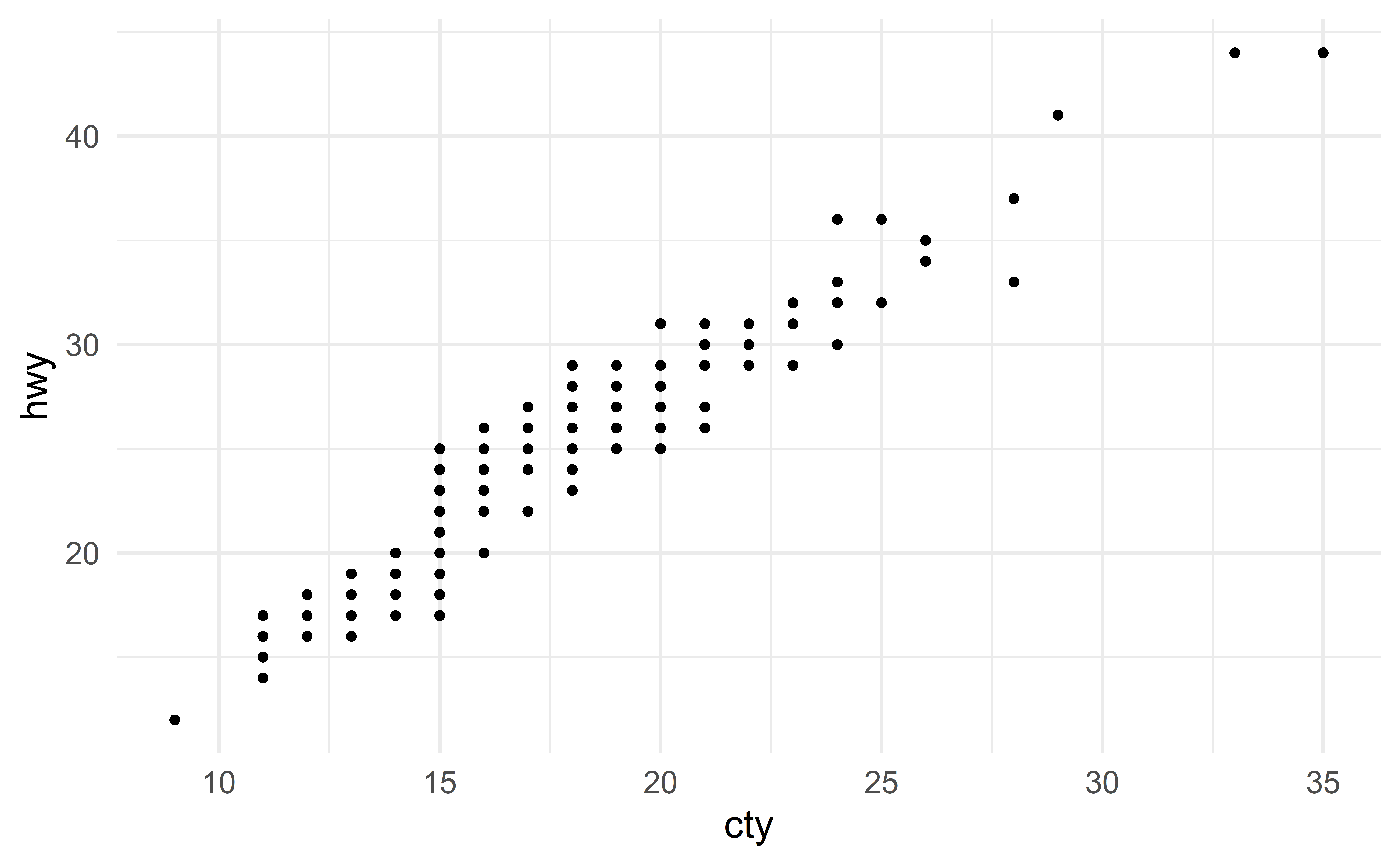
The variables cty and hwy are linearly associated.
We therefore opt for a simple linear regression model
\[ \text{hwy} \approx \beta_0 + \beta_1 \text{cty} \]
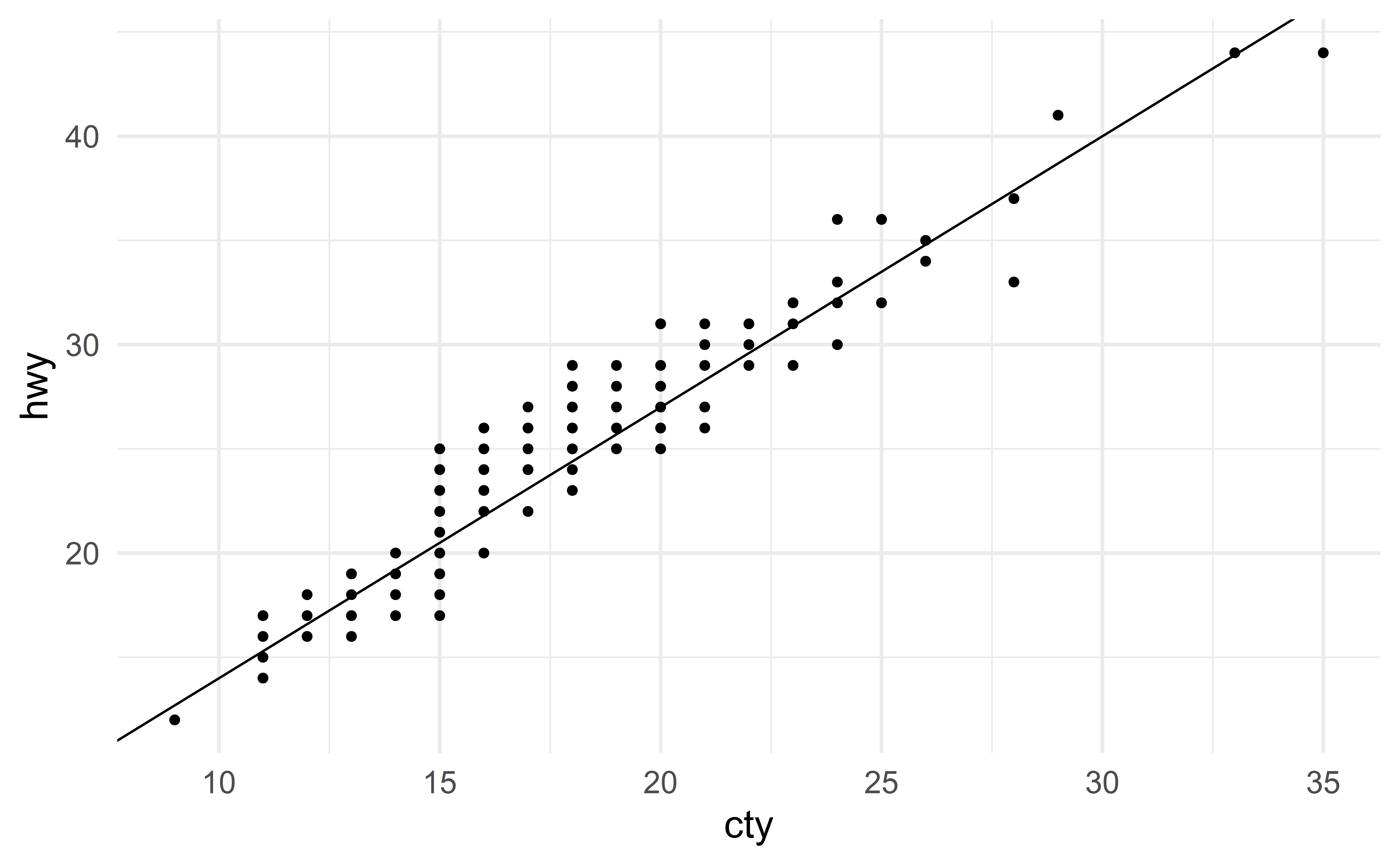
Visualizing residuals
- Black circles: Observed values (\(\text{hwy}\))
- Pink solid line: Least-squares regression line
- Maroon triangles: Predicted values (\(\widehat{\text{hwy}}\))
- Gray lines: Residuals
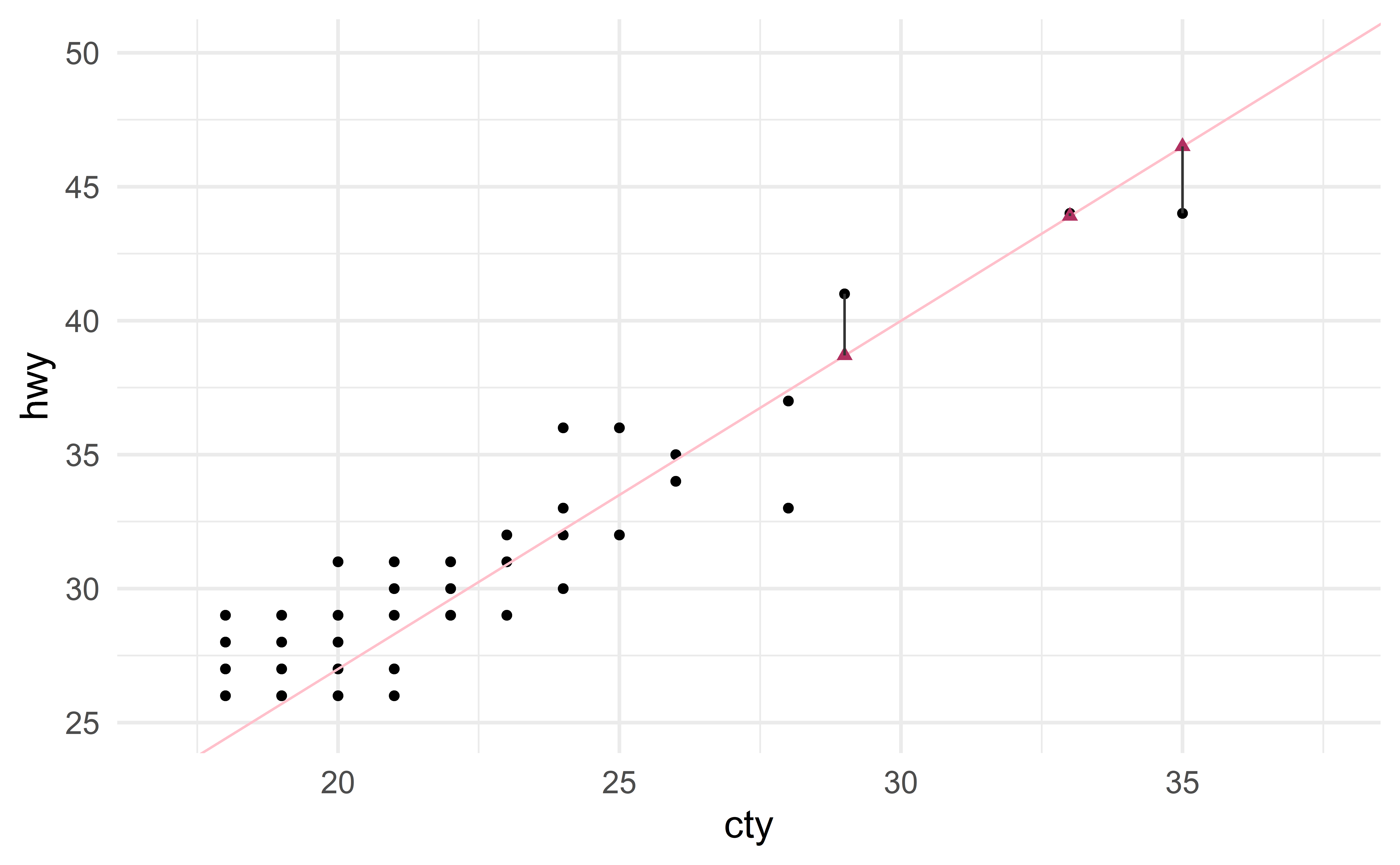
Residual plot
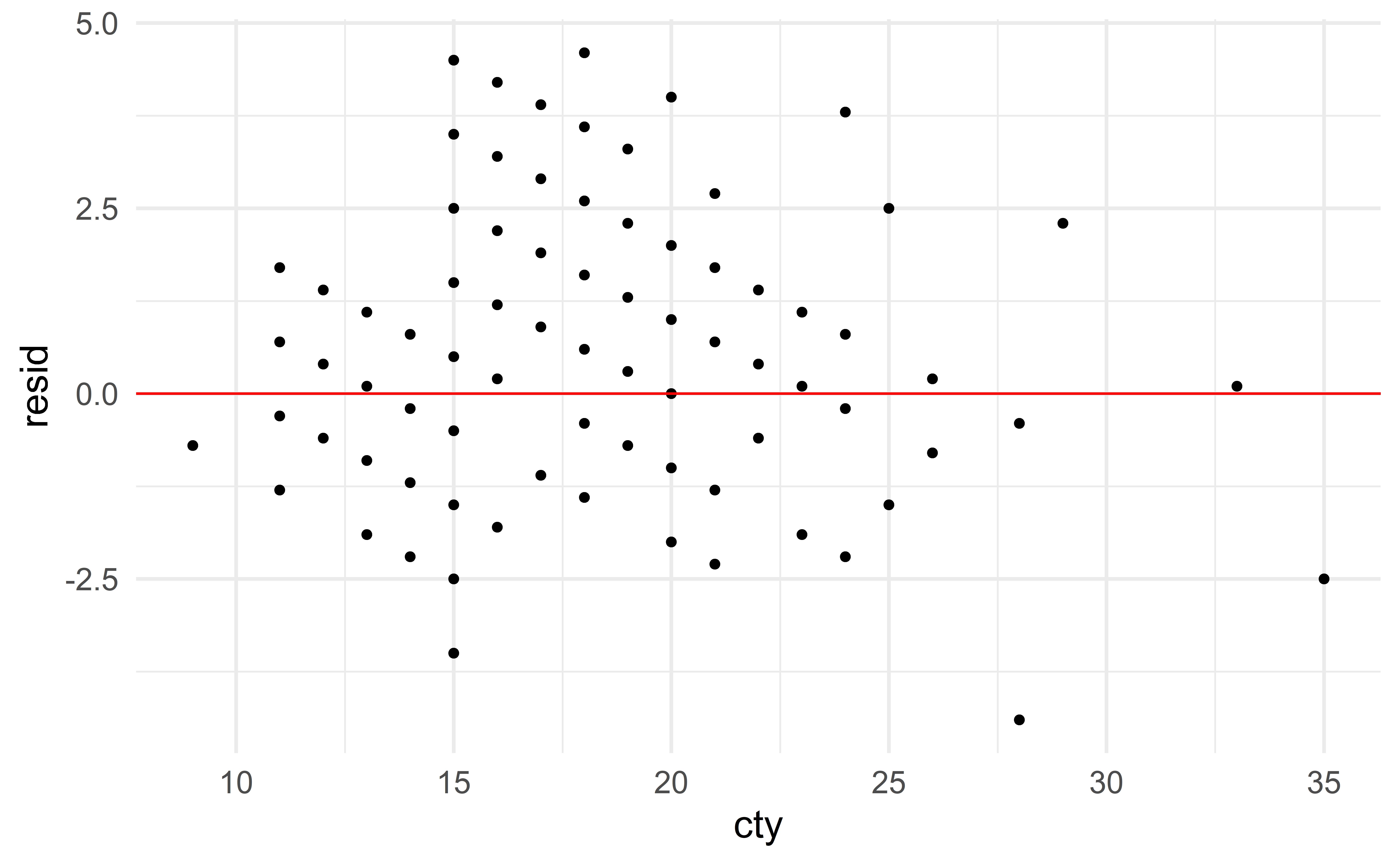
Assessing linearity with residual plots
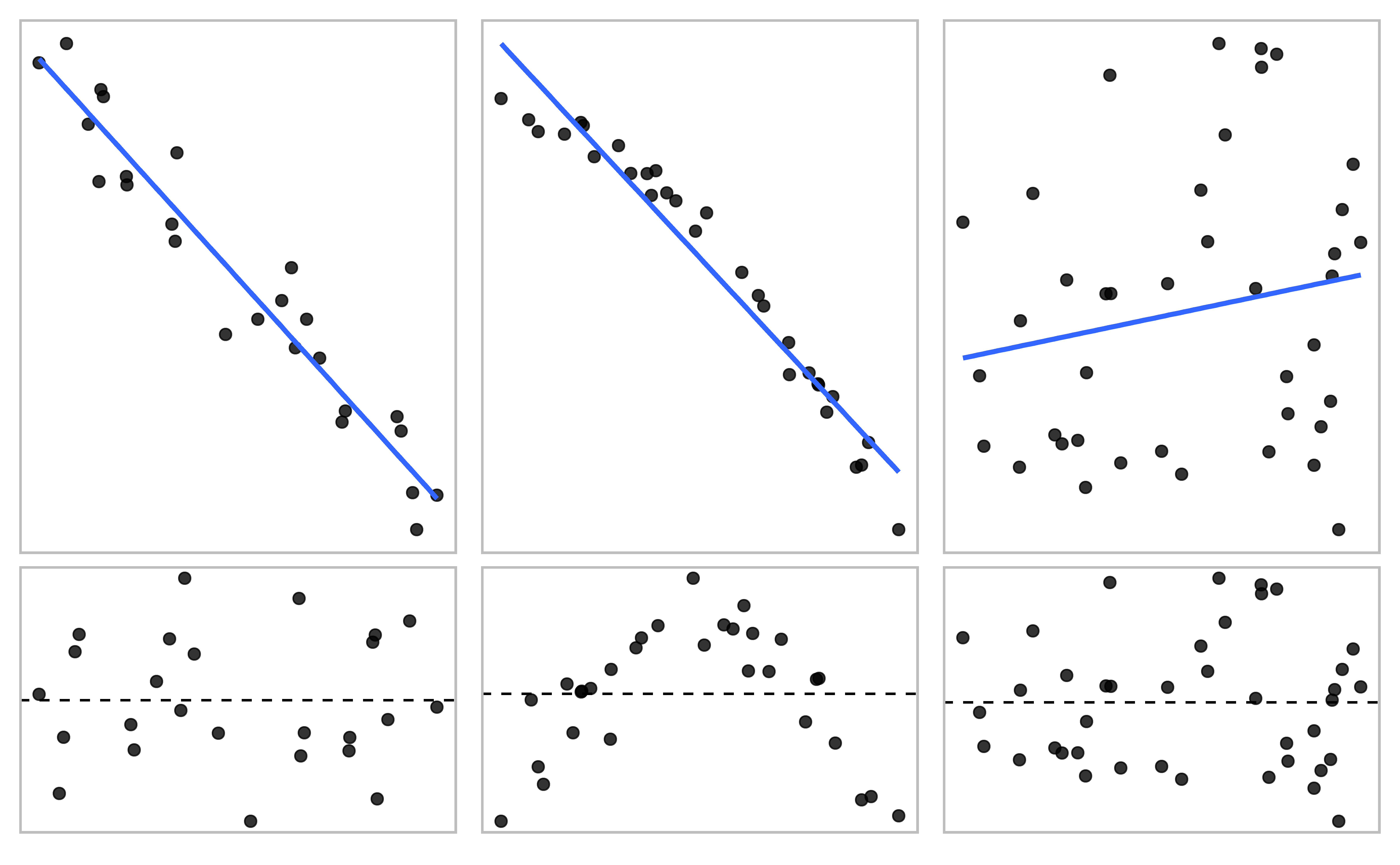
Source: IMS
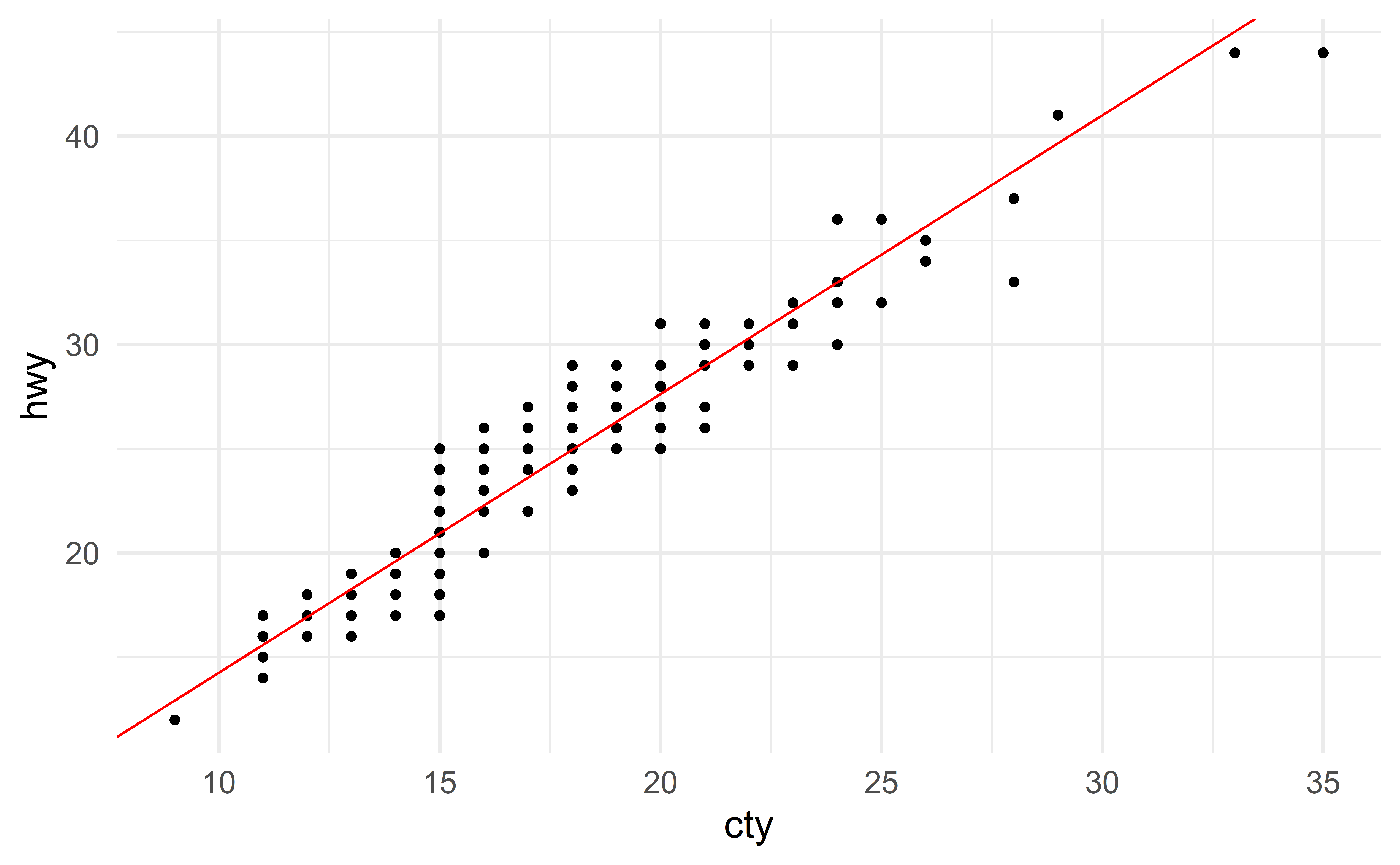
Visualizing the least square regression line
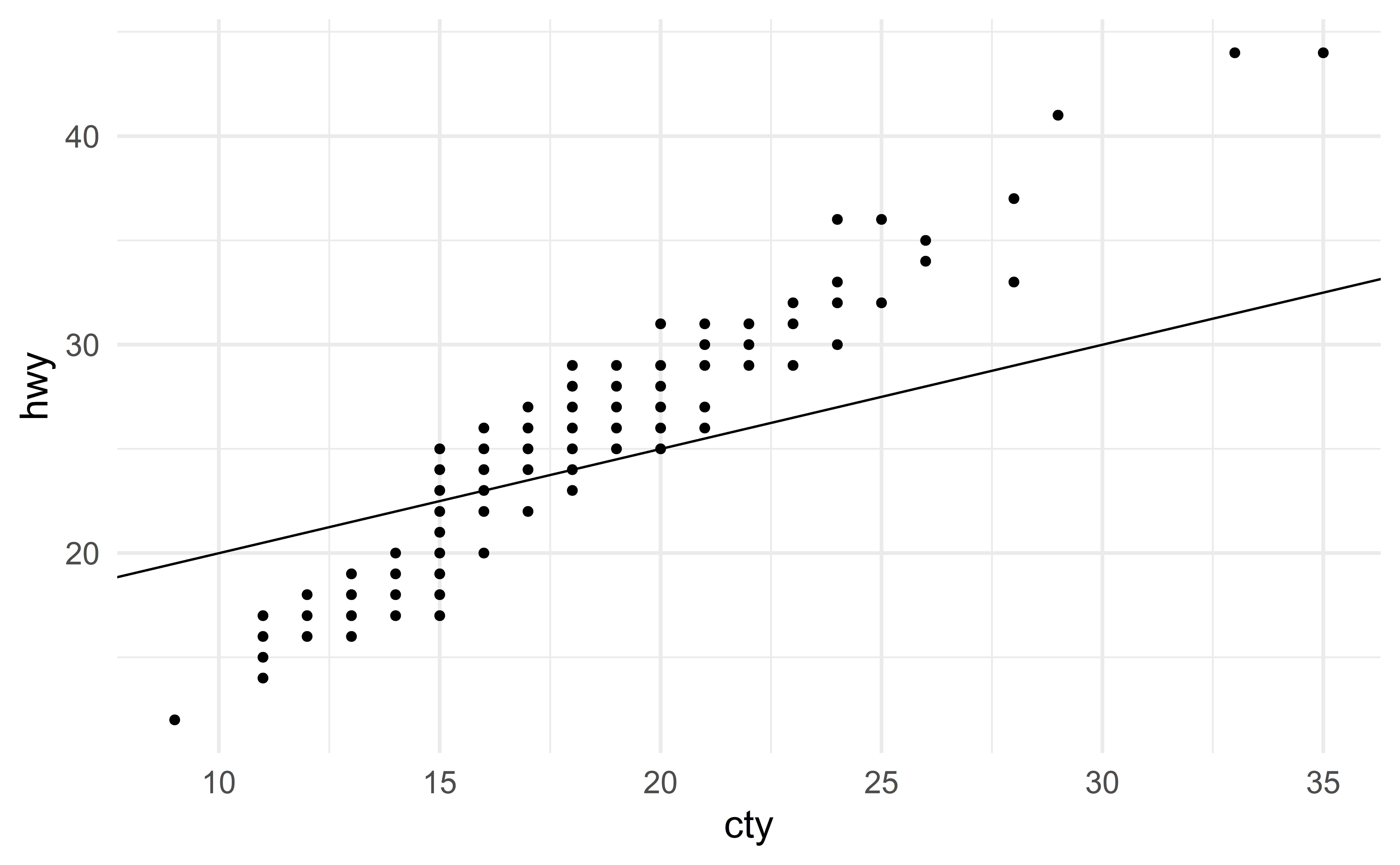
Alternative model
Let us fit an alternative model using engine size (disp) as a predictor
\[ \text{hwy} \approx \beta_0 + \beta_1 \text{displ} \]
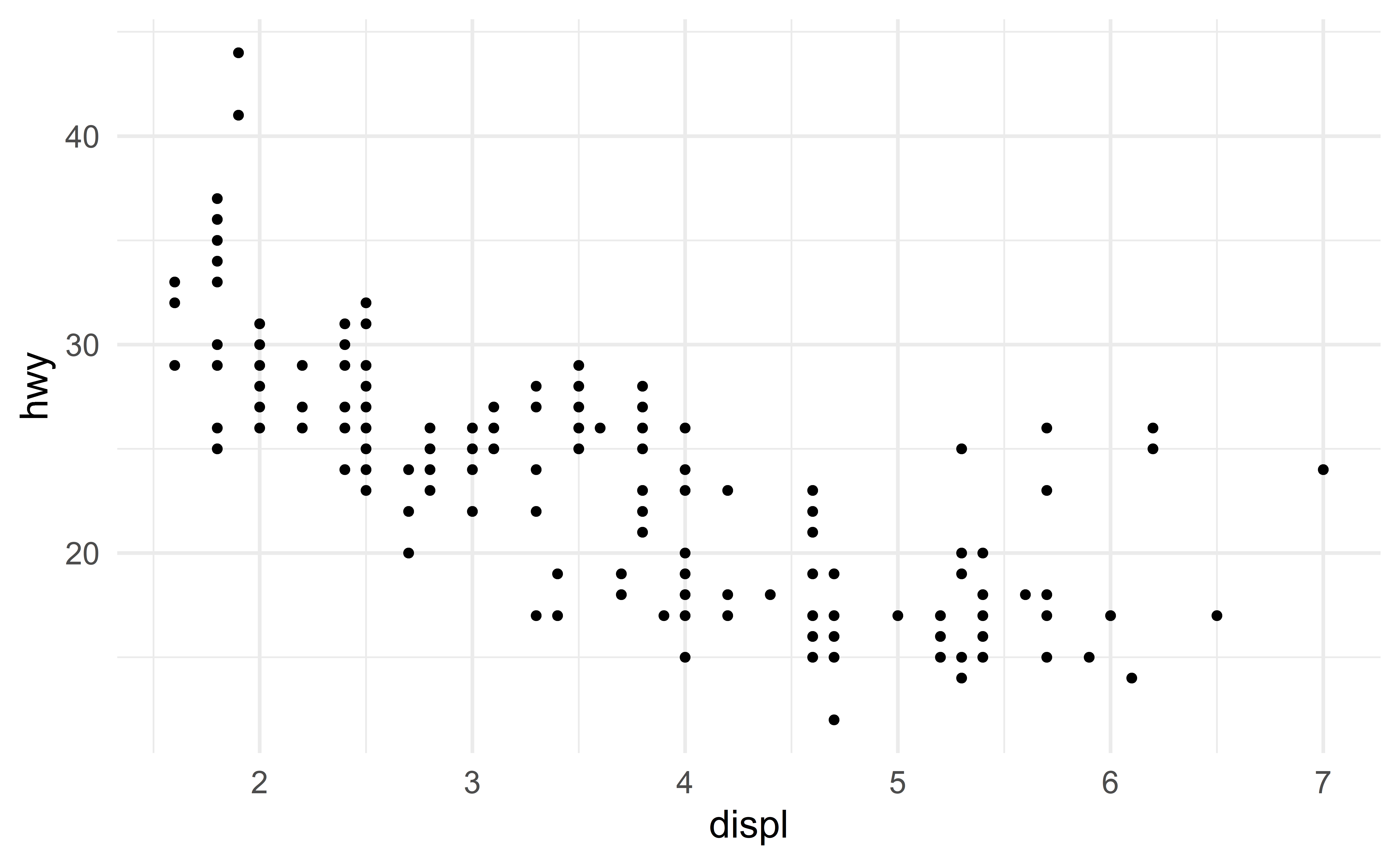
Comparing residuals
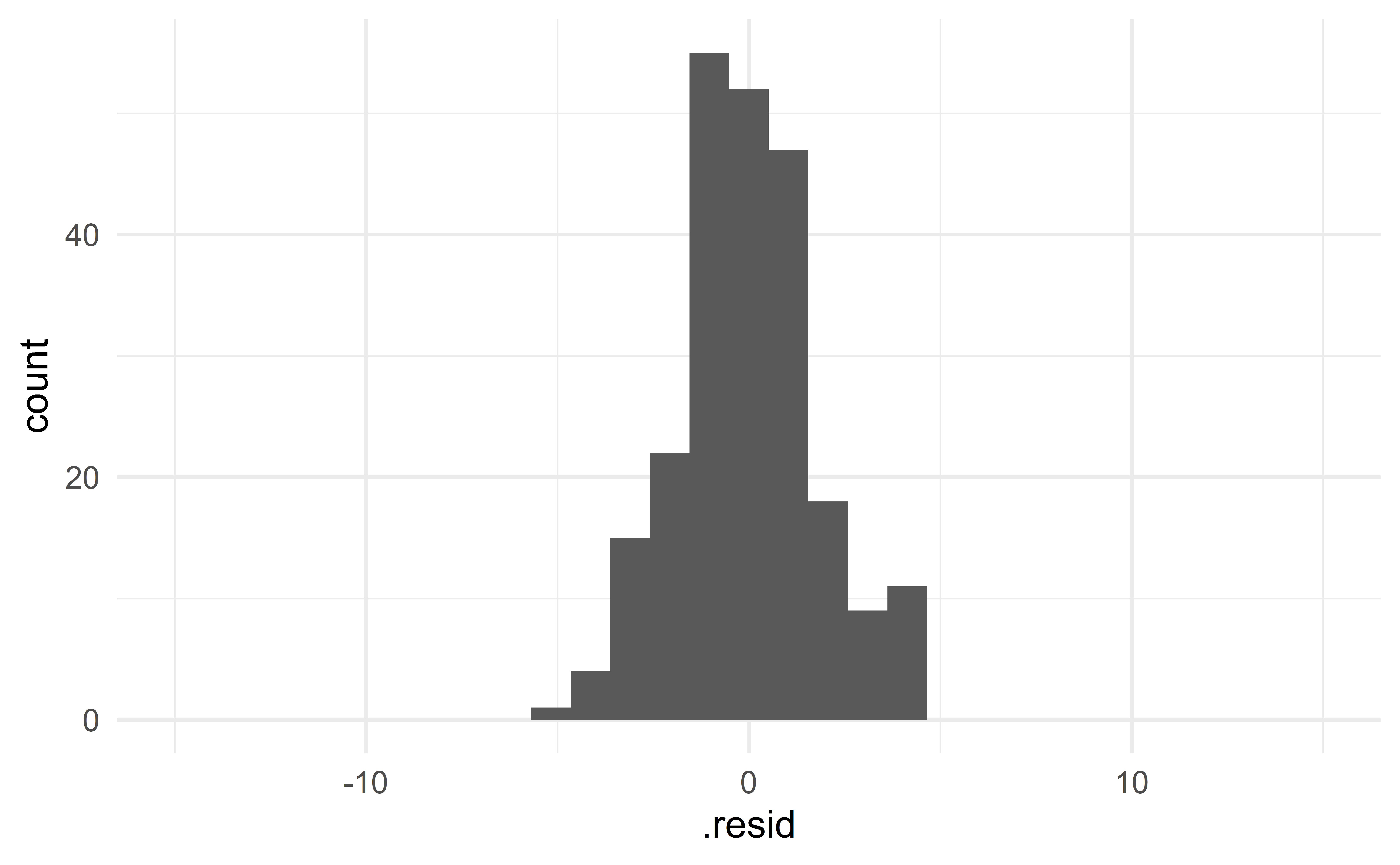
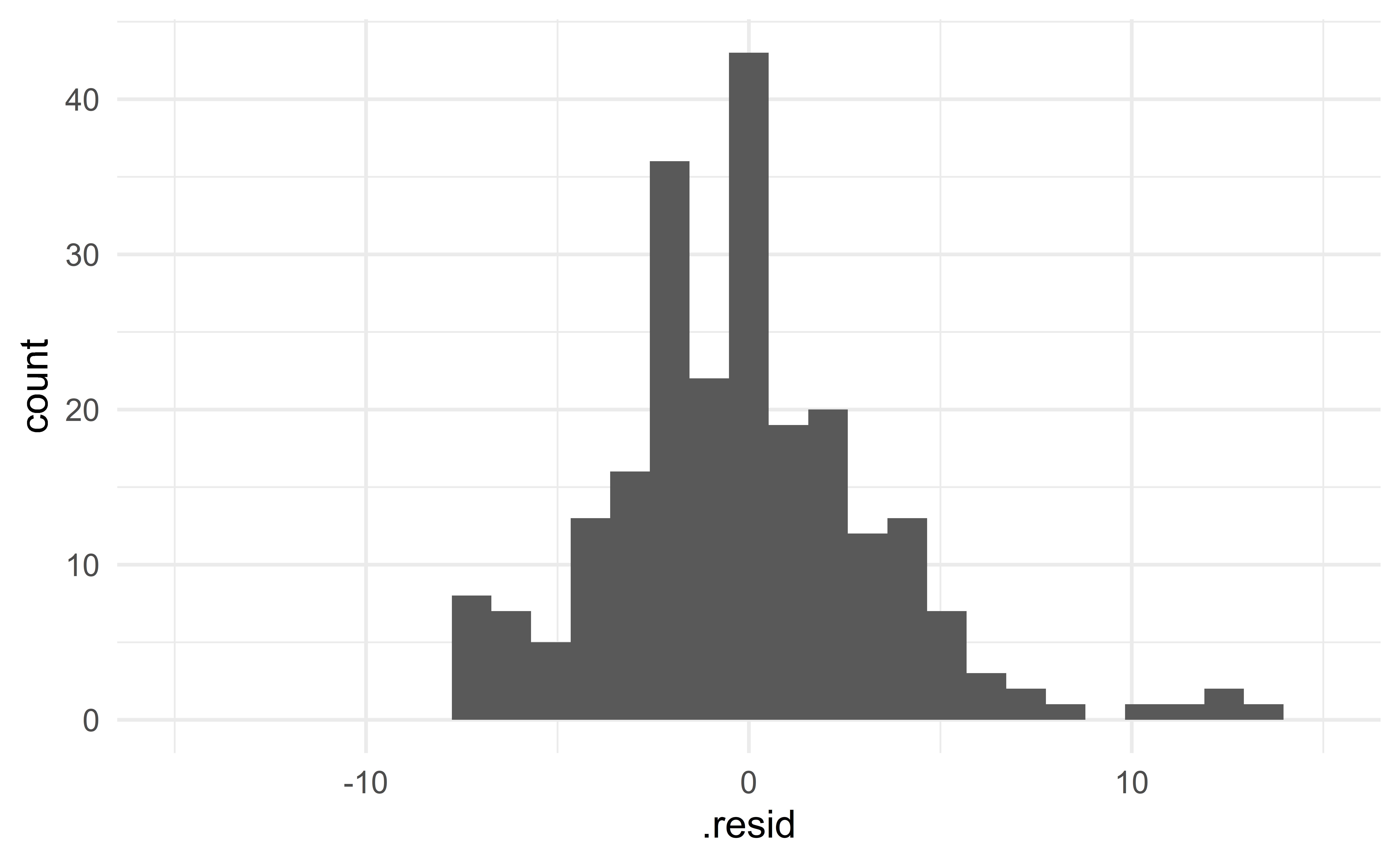
The first model seems to have smaller residuals.
\(\Rightarrow\) choose the first model!
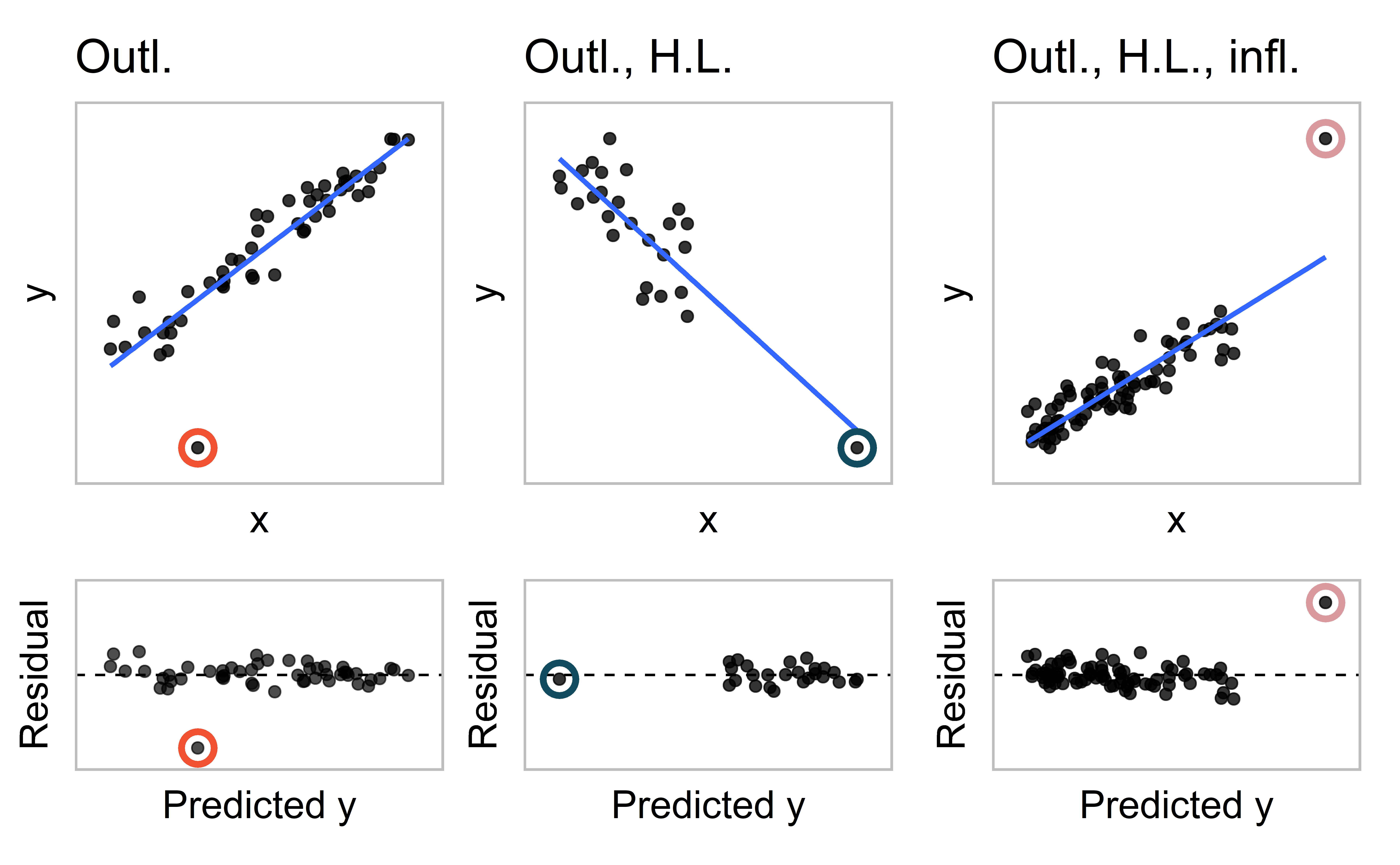
Outliers in regression
Remember, in a boxplot, outliers are observations far from the bulk of the data
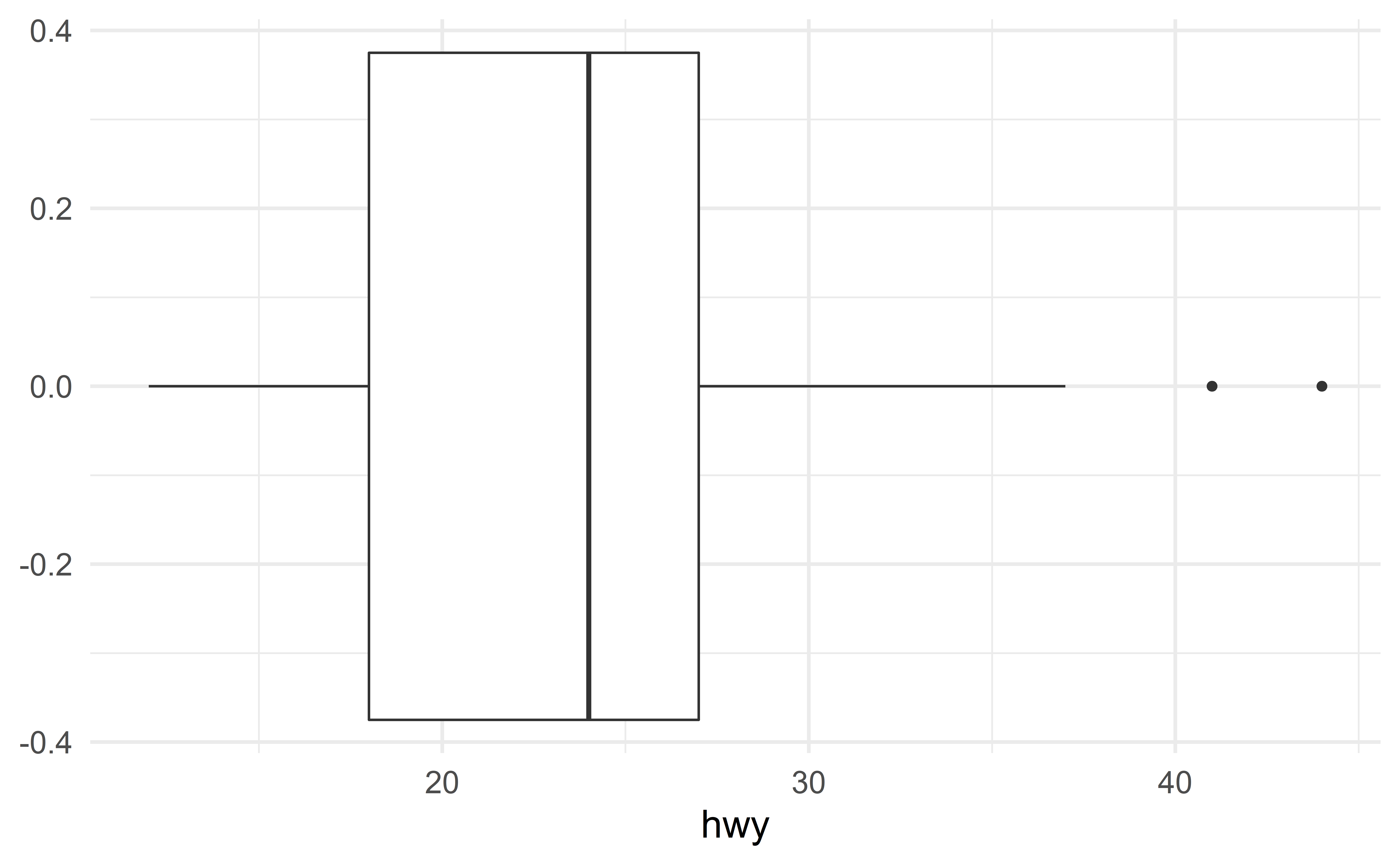
In the context of regression models, an outlier is an observation that falls far from the cloud of points
Identifying outliers
In the following scatterplot, we see two outliers
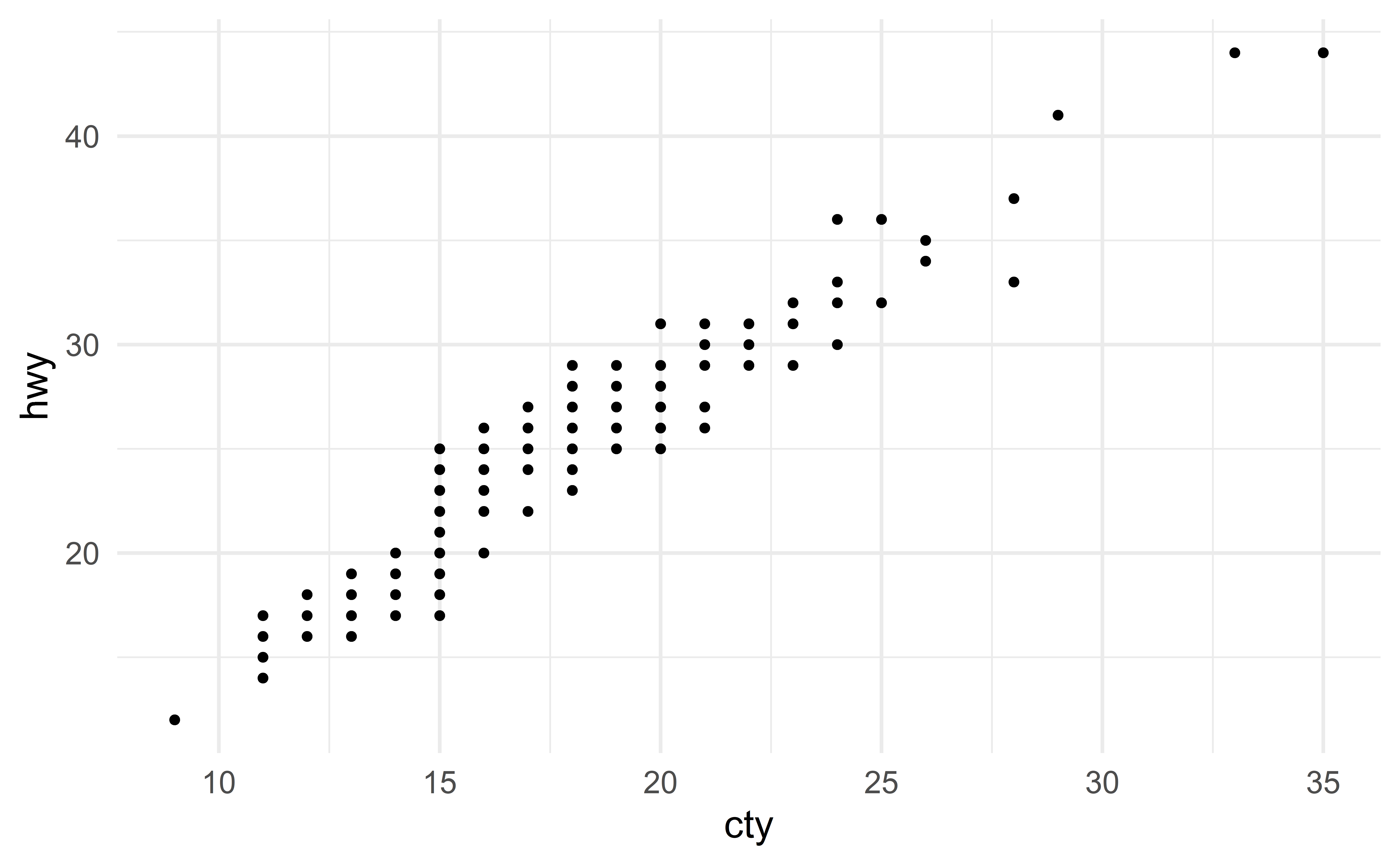
Source: IMS
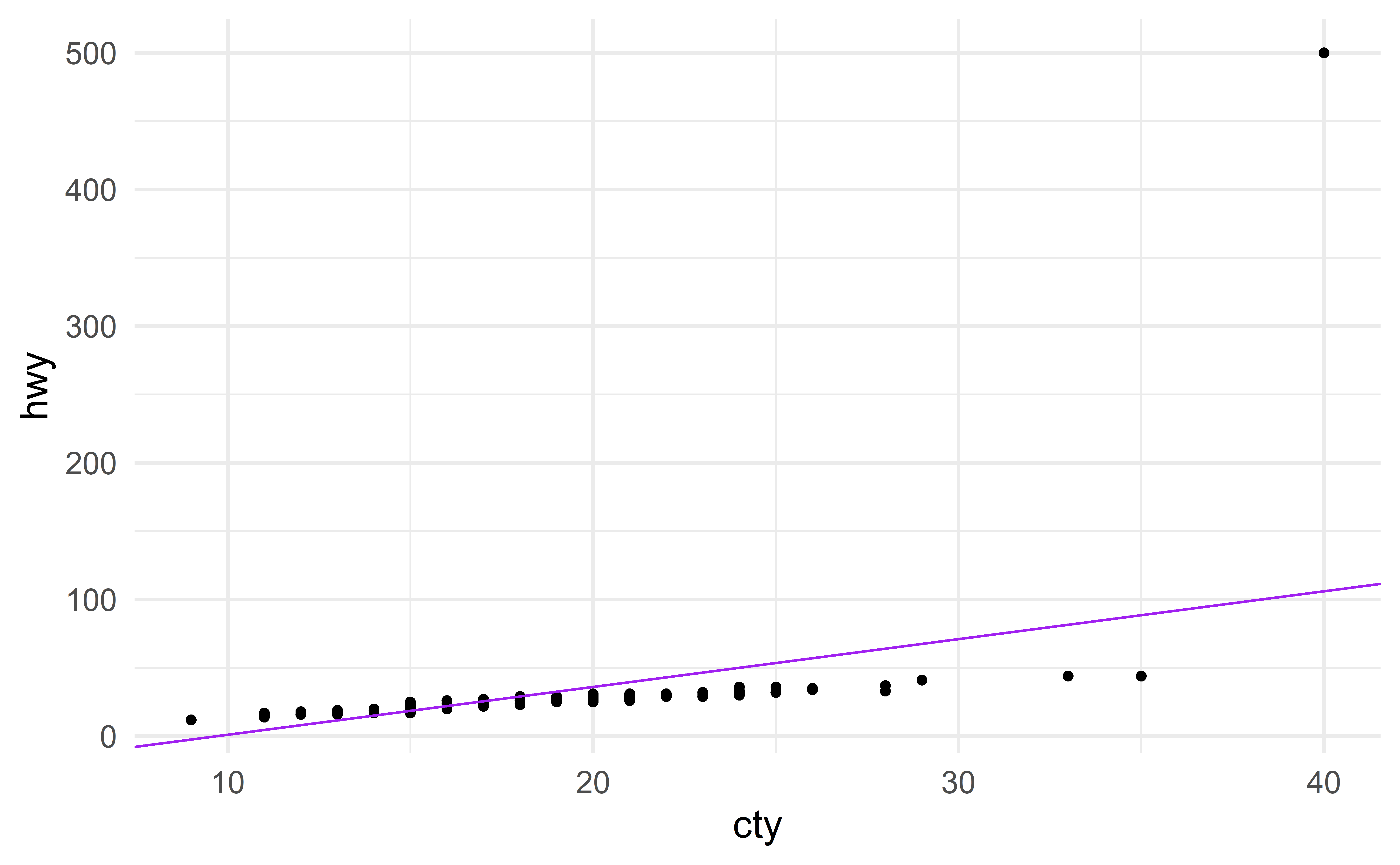
The regression line not longer fits the data well.
Recap
- simple linear regression model
\[ \text{hwy} \approx \beta_0 + \beta_1 \text{cty} \]
- residuals
- least-square estimates
- parameter interpretation
- model comparison with \(R^2\)
- outliers