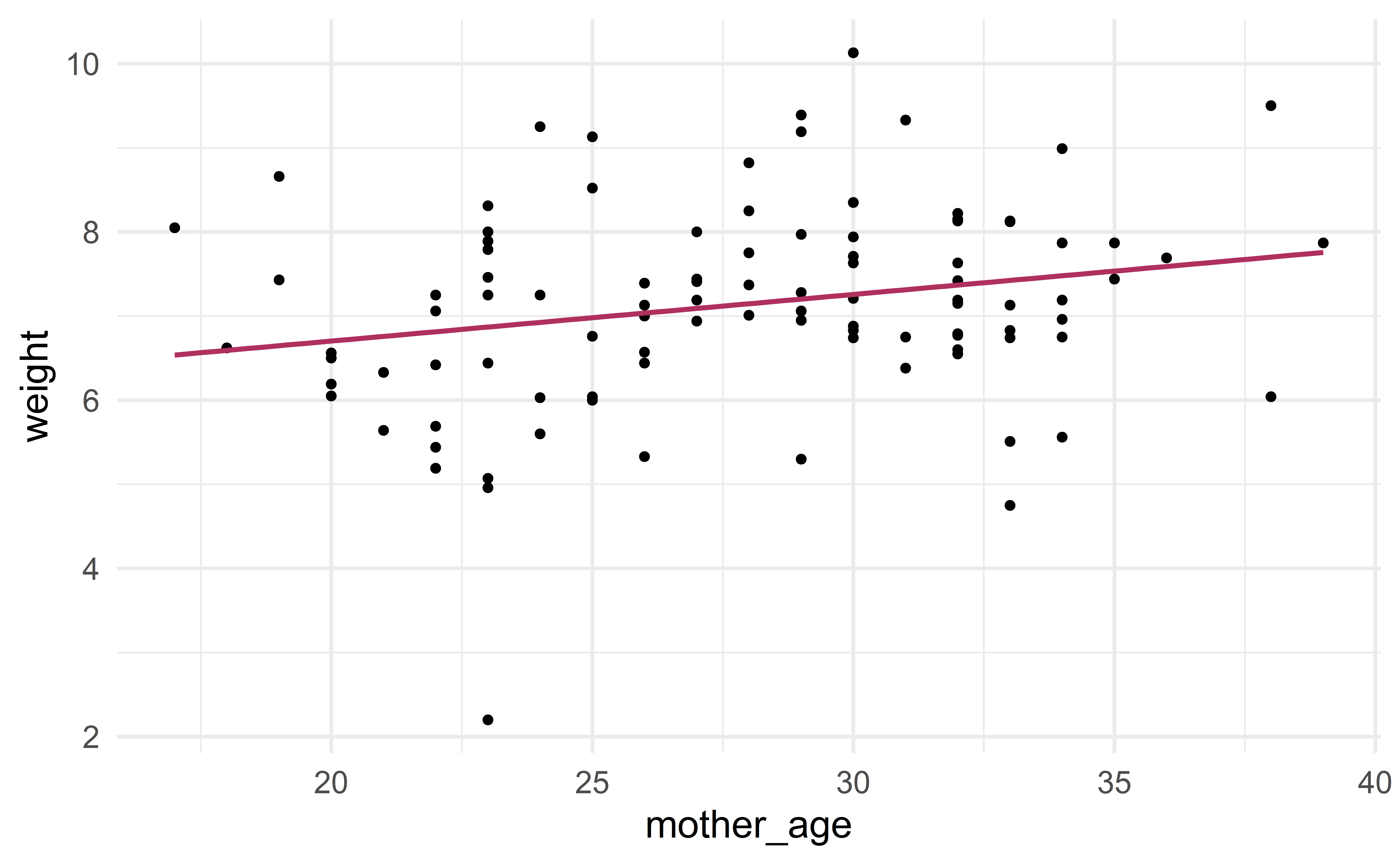
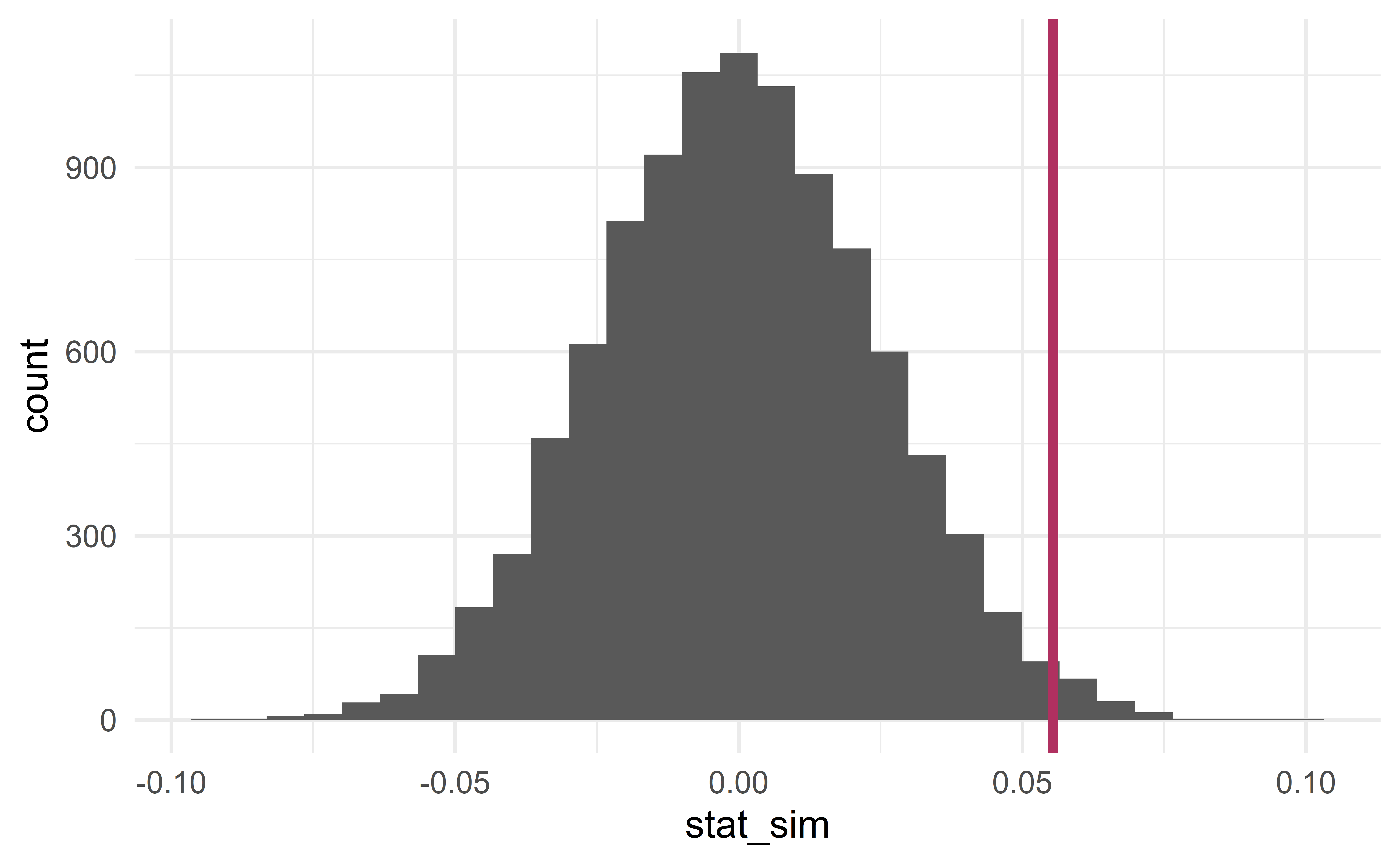
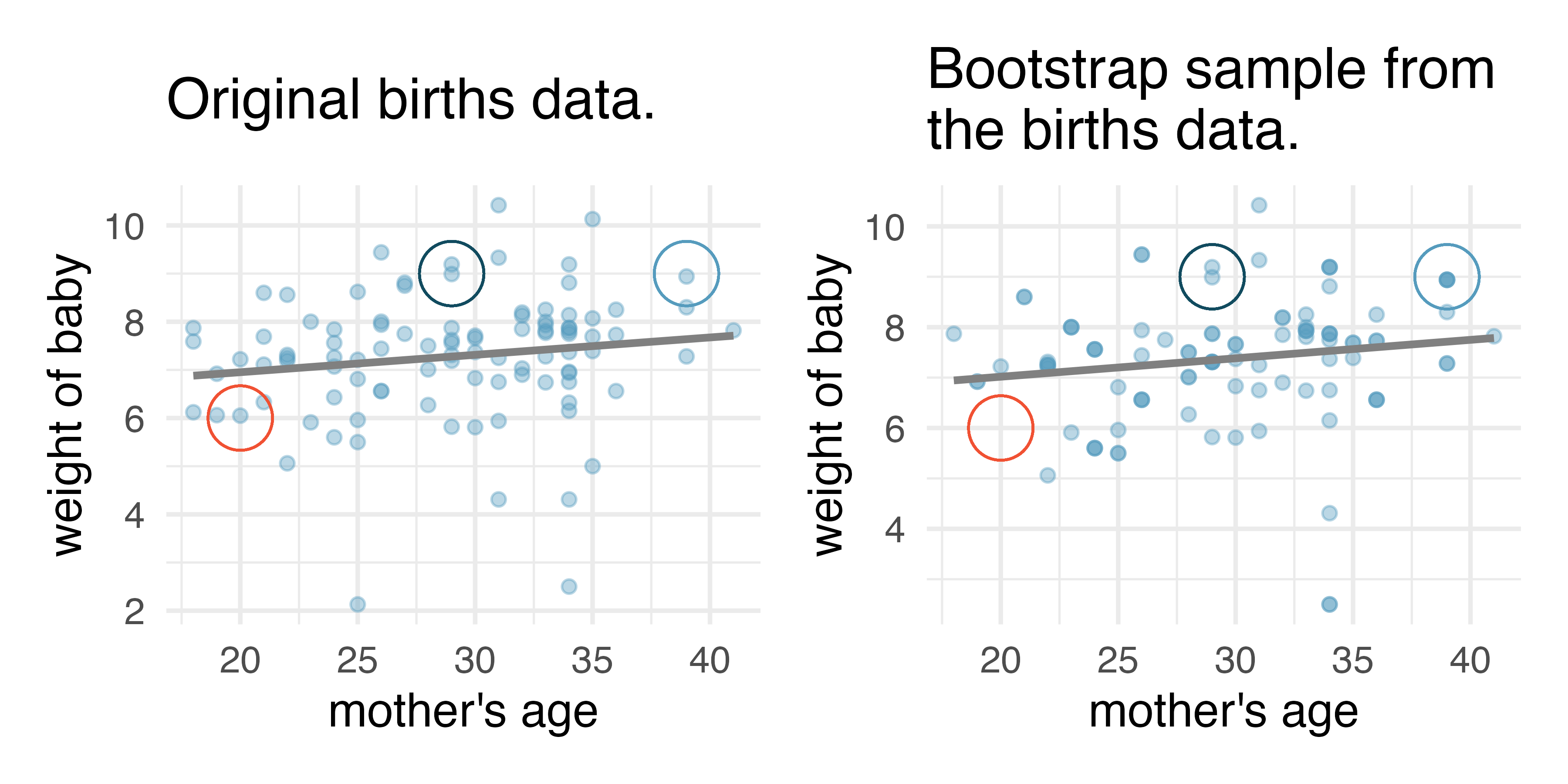
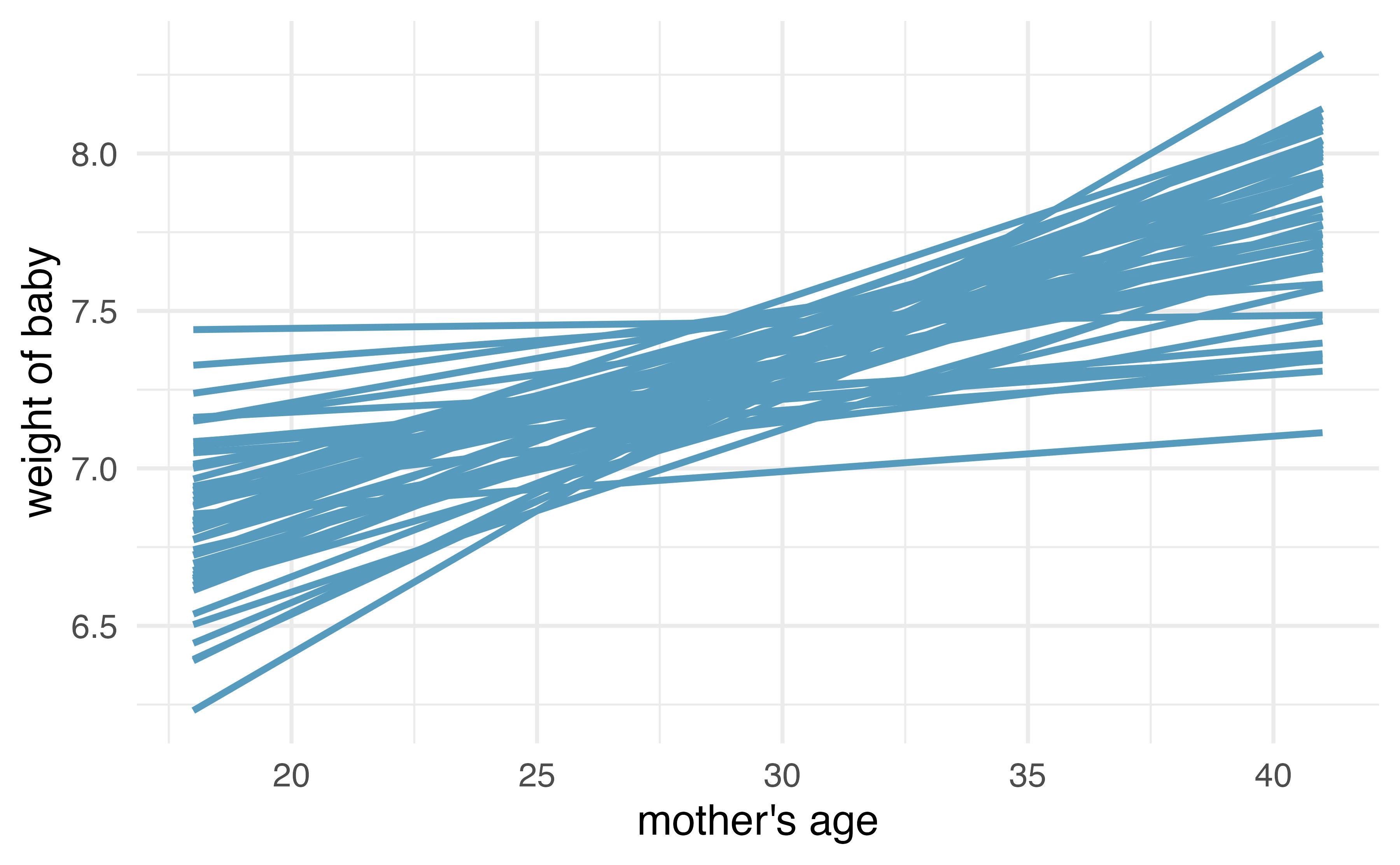
set.seed(47)
d <- openintro::births14 %>%
sample_n(100) %>% # take a random sample of 100 births
select(weight, mage) %>% # only keep the variables weight (newborn's weight) and mage (mother's age)
rename(mother_age = mage)
head(d)# A tibble: 6 x 2
weight mother_age
<dbl> <dbl>
1 6.94 27
2 9.19 29
3 7.39 26
4 8.82 28
5 7.87 35
6 9.39 29